Bergés Nieto está reinventando la experiencia del paciente en la clínica dental
Clínica dental en Sant Feliu de Llobregat
Te ofrecemos mucho más. Bergés Nieto no es únicamente un clínica dental en Sant Feliu de Llobregat, si no un centro de alta especialización dental, en el que la excelencia en los tratamientos y la atención de nuestros pacientes sean premisas fundamentales.

El equipo
Un equipo joven y dinámico a tu disposición, formado por profesionales altamente cualificados en cada área de la odontología y en constante formación. Preparados y dispuestos a ayudarte en todo aquello que necesites.
Cada paciente que llega a nuestro centro dental es para nosotros una nueva ilusión y un nuevo reto, por eso, no podemos más que ofrecerle una atención excelente y totalmente personalizada. Para ello, contamos con especialistas altamente cualificados en cada área odontológica.
Respaldamos la especialización y el excelente trato de nuestros especialistas y técnicos con unas modernas instalaciones en el corazón de Sant Feliu de LLobregat y los últimos avances tecnológicos.
Queremos demostrar que nuestros pacientes pueden disfrutar de la odontología, mejorando la experiencia de ir al dentista desde la primera visita, promoviendo la prevención y realizando una odontología responsable basada en mínima intervención.
Primera visita sin coste
Últimas Reviews en Google










Descubre nuestros tratamientos de alta especialización y cualificación
Ortodoncia
Expertos en todo tipo de aparatos ortodóncicos. Ortodoncia estética e invisible en adolescentes y adultos y en ortopedia dentofacial infantil.
Prótesis dentales
Centro especializado en rehabilitaciones protésicas estéticas. Sobre dientes o implantes, fijas o removibles, parciales o completas.
Endodoncia
Empleamos la tecnología más vanguardista, planificación digital con escáner 3D, para acometer endodoncias microscópica y microcirugía endodóntica.

Periodoncia
Tratamientos para las enfermedades de la encía, la gingivitis, la periodontitis y la periimplantitis, y los tejidos circundantes a los dientes o implantes dentales.
Cirugía e implantes
Centro especializado en implantología dental avanzada, rehabilitaciones completas con diagnóstico digital en 3D, y sedación profunda o consciente.
Estética dental
Soluciones estéticas para cualquier caso. Especialistas en tratamientos mínimamente invasivos y diseño de sonrisas digital.

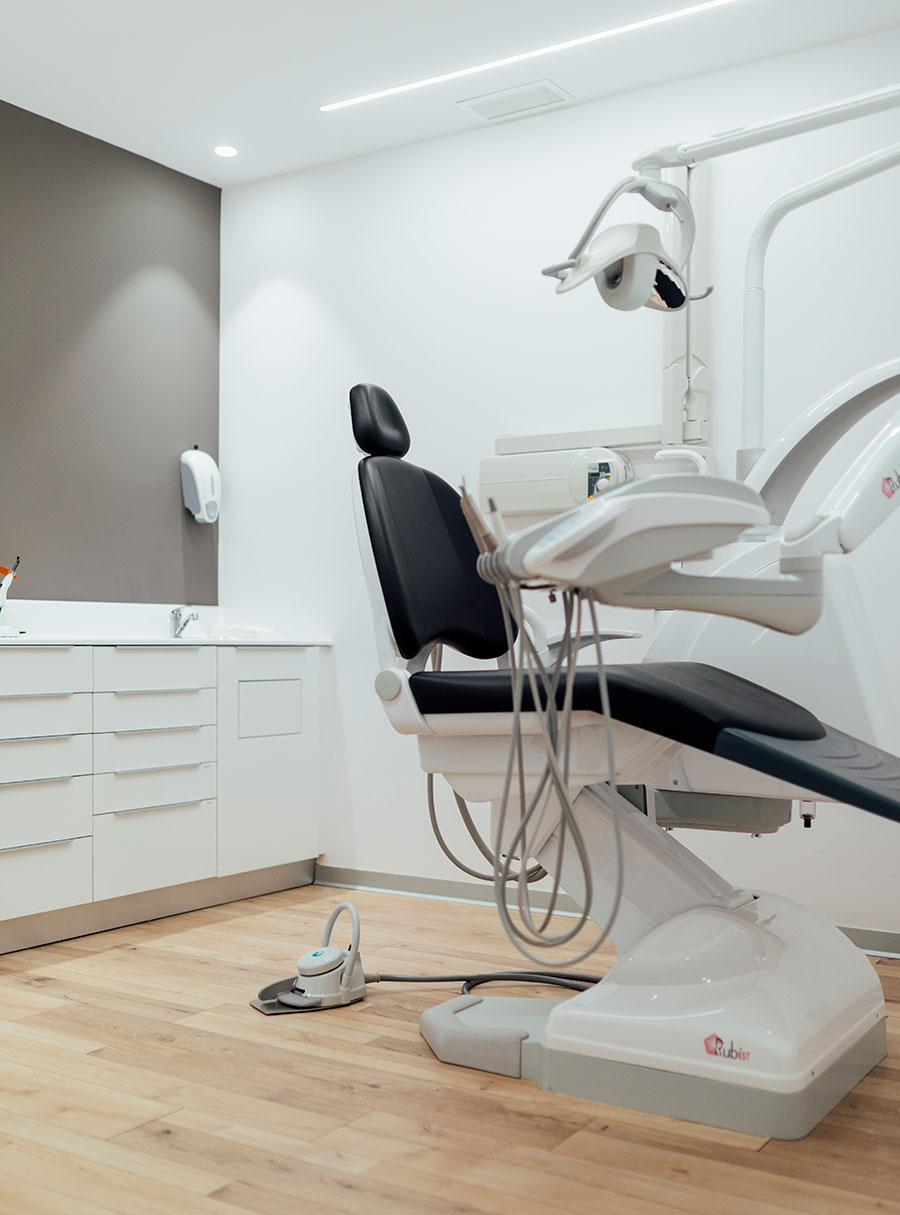


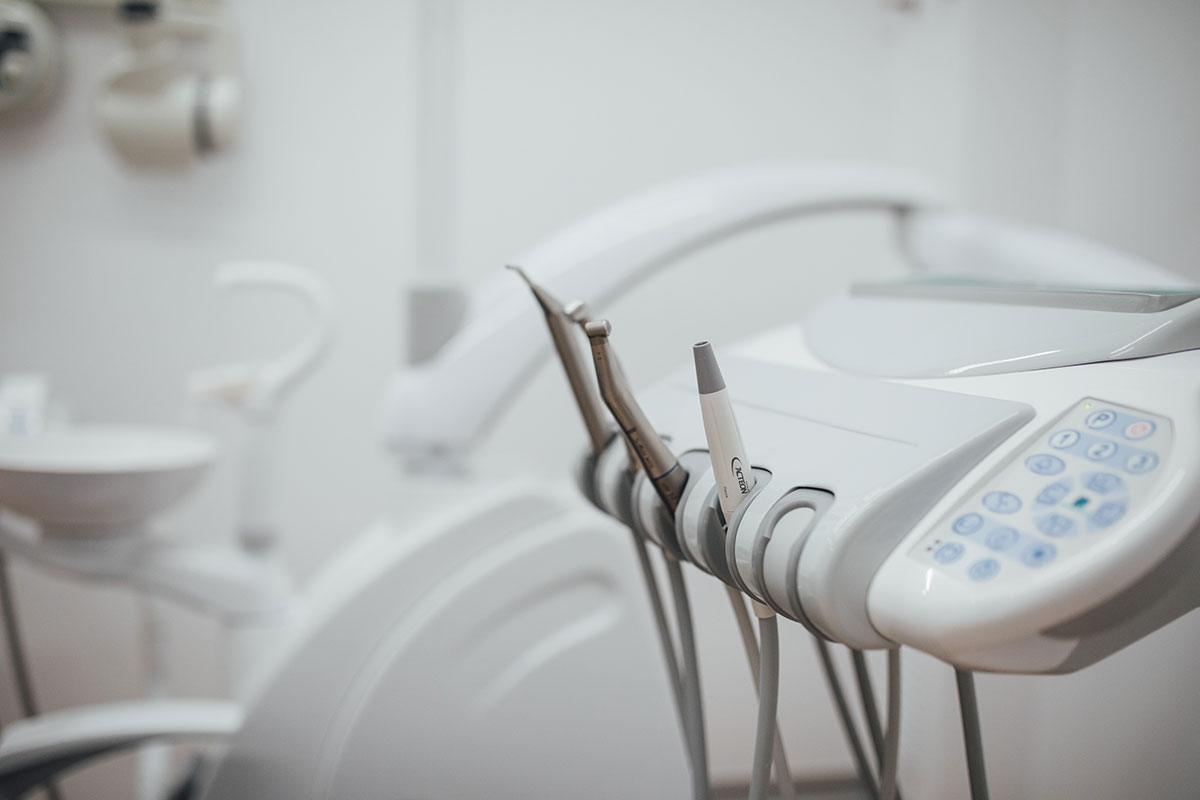

Clínica Dental Sant Feliu de LLobregat
Si estás buscando una clínica dental en Sant Feliu de LLobregat que ofrezca los tratamientos más avanzados, puedes confíar en Bergés Nieto. Las doctoras Mentxu Bergés y María Nieto han configurado un equipo especialistas en odontología, implantología, cirugía oral y ortodoncia, al que han añadido la implementación de las últimas tecnologías en salud bucodental y equipos de diagnóstico. Por eso te recordamos que si quieres mejorar tu salud bucodental mediante las técnicas más innovadoras del mercado, las puedes encontrar en nuestro centro odontológico. Además, si por algo nos caracterizamos, es por ofrecer a los pacientes y asesoramiento 100% personalizado y a medida, así como un trato amabñe y cercano. Buscamos el tratamiento que mejor se ajuste a tus necesidades: Prótesis dentales, ortodoncias, implantes, tratamientos blanqueantes…
En nuestra clínica dental en Sant Feliu de LLobregat encontrarás un centro odontológico con precios asequibles. Además implantamos el sistema de anestesia indolora, para que nuestros pacientes disfruten en la consulta de una experiencia libre de estrés o ansiedad.
Una clínica dental en Sant Feliu de LLobregat con los tratamientos más innovadores a tu alcance
Desde nuestra experiencia en centros de alta especialización dental, podemos afirmar que para nosotros lo más importante es abordar cada caso de manera personalizada. Alinear tus dientes mediante una ortodoncia de calidad o realizar un tratamiento de última generación con implantes dentales en Sant Feliu de Llobregat, ahora es posible. Por eso, no lo dudes más, nunca fue tan fácil como ahora disfrutar de una bonita sonrisa.
Si buscas un centro especializado en odontología en Sant Feliu de Llobregat, con precios asequibles y una atención excelente al paciente, ven a visitarnos. Estaremos encantados de recibirte.
Tu dentista en Sant Feliu de LLobregat
En la clínica dental Bergés Nieto tendrás la posibilidad de acceder a un dentista en Sant Feliu de Llobregat con la tranquilidad que aporta tener el poyo de todo un equipo de especialistas en odontología de experiencia consumada velando conjuntamente por tu salud bucodental.
Ponemos a tu entera disposición nuestro equipo de dentistas, plenamente capacitados para dar siempre la respuesta más adecuada a cualquier problema o anomalía que perjudique tu salud o estética dental. Así mismo, contamos con las instalaciones de una clínica moderna completamente equipada con los avances técnicos necesarios y así, proporcionarte los tratamientos más novedosos.
El dentista en Sant Feliu de Llobregat, que estabas buscando
Nuestras capacidades van mucho más allá, puesto que nuestra oferta de servicios. Puesto que además de contar con un amplio equipo de doctores que abarca todas las especialidades dentales, disponemos de un equipo de auxiliares y recepcionistas que convertirán tu paso por nuestra clínica en algo agradable y querrás volver a visitarnos.
No pospongas más el tratamiento que va a mejorar definitivamente tu sonrisa. La falta de tiempo o un precio excesivo son muchas veces los argumentos para no considerar ningún momento lo suficiente mente bueno para acudir a tu cita con el dentista.
No dejes más que el tiempo pase y persistan esos los pequeños defectos en tu sonrisa, que tanto te incomodan. Si deseas verte mejor, acabar con los inconvenientes a la hora de comer o los complejos al sonreír, ven a visitarnos, ahrora tienes un dentista en Sant Feliu de Llobregat que resolverá todos estos problemas en un tiempo récord y sin que debar realizar un gran desembolso. Te esperamos!
Preguntas frecuentes
¿Se pueden financiar los tratamientos?
En nuestra clínica ofrecemos todo tipo de alternativas para hacer frente a la parte económica de nuestros tratamientos. Desde el primer momento que entres por la clínica te acompañaremos en todo el proceso de tu tratamiento y te daremos las mejores soluciones para financiar tu tratamiento dental en diferentes plazos, llegando hasta los 24 meses sin añadir ningún tipo de interés.
¿Cuánto cuesta una primera visita?
No tienes que preocuparte ya que la primera visita que nos hagas será totalmente gratuita. Solo tendrán un coste añadido si llevas ortodoncia de otra clínica y necesitas una segunda opinión o las visitas de odontopediatría, que variará según la edad del paciente.
Si tengo un tratamiento ya empezado, ¿podríais continuar con él?
Antes de retomar un tratamiento ya empezado en Clínica Dental Bergés Nieto siempre valoramos el estado actual de dicho tratamiento. Esto nos ayudará a tomar la decisión más adecuada, ya que puede darse el caso, como en ortodoncia, de que lo mejor sea comenzar el tratamiento otra vez desde cero. Nuestra filosofía es que en ocasiones es más sencillo empezar desde cero con una boca sana que arreglar tratamientos que ya están a medias.
¿Qué hago si tengo una urgencia?
Tanto si eres paciente nuestro como si no, no dudes en ponerte en comunicarte con nosotros por cualquiera de nuestras vías de contacto: Teléfono: 930 150 456 o mail: info@clinicadentalbergesnieto.com
¿Trabajáis con mutuas o asociados?
No trabajamos con mutuas o asociados ya que estas obligan a las clínicas a trabajar por precios inferiores a los habituales. Tanto en las mutuas como asociados los pacientes pagan una cuota y reciben un tratamiento más económico que lo habitual, lo que fuerza a las clínicas dentales que trabajan con mutuas a ir más rápido, atender a más pacientes para compensar lo que sería una facturación corriente. Además dichas clínicas también abaratan costes reduciendo presupuesto en materiales más baratos y de menor calidad. La palabra “low cost” para nosotros no existe en el campo de la ortodoncia y trabajar a volumen es contraproducente. En Clínica Bergés Nieto vuestra salud dental es siempre lo primero y nunca escatimaremos ni en materiales ni en ofreceros siempre un trato totalmente personalizado.

Sin esperas
Trato exquisito
Respeto por el diente
Facilidades de pago
Solicita tu próxima cita en nuestra clínica
Estamos en
Carrer Pi i Margall 37
08980 Sant Feliu de Llobregat
Barcelona
HORARIO
Lunes a viernes 10:00 – 14:00 y 16:00 – 20:00
Sábados y Domingos Cerrado